Thank you for providing a detailed description of your processing steps! This makes it possible to reproduce your experience.
TeddyHuang wrote: ↑Wed Jun 26, 2024 3:57 pm
1) I used examples
/01-dynamic-compression/1speaker_diffNoise_2ch.wav
as my input audio file.
2) I used 94 dB as the acoustic input level in dB SPL.
94 dB SPL peak level is a reasonable estimation for audio file 01-dynamic-compression/1speaker_diffNoise_2ch.wav in my opinion. It puts the sound levels in this file at 71 and 72 dB SPL, which given the lack of strain in the speaker's voice and the addition of noise is within the reasonable range somewhere near 70dB SPL for this sound. Make sure to adjust the peak level to the recording situation for other sound files, the best of course would be to calibrate your recording setup.
3) I simulated an audiogram with the following values: [20, 30, 40, 50, 60, 70, 80, 80, 80] for [250, 500, 1k, 1.5k, 2k, 3k, 4k, 6k, 8k] Hz.
4) Then I applied NAL-NL2 as the gain amplification strategy and created the first fit.
5) I used the default values of the first fit without making any manual adjustments.
6) I saved the file and exited the fitting tool.
7) When I played the saved wav file, I couldn't hear any sound. Based on the description in a related topic, I amplified the output sound file by 50 dB and could hear the sound (I'm not sure if this step was correct).
You may be referring to
viewtopic.php?t=162#p398. The offline fitting tool informs about the added headroom for amplification in this screen:
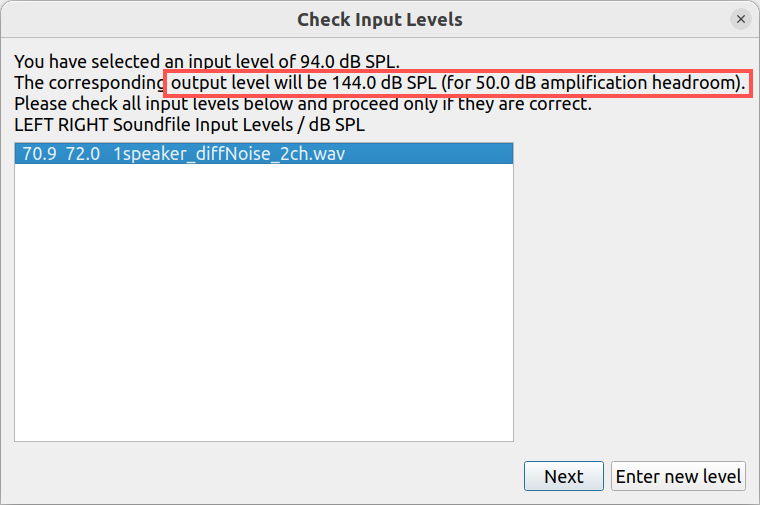
- OutputPeaklevelInfo.png (49.99 KiB) Viewed 63366 times
When I repeat your steps, then I find that If I amplify the output file by 50dB, then a few samples get clipped. You should not amplify output files by 50 dB without checking for clipping.
If I want to play back unprocessed and processed files through headphones with the same settings, then I would amplify the processed sound by 45 dB and attenuate the unprocessed sound by 5 dB, and then adjust an analogue amplifier so that the unprocessed sound is actually played back at your chosen 71-72 dB SPL. The processed sound will then play at 81dB SPL.
8)The sound that played back had severe mechanical noise and sounded very unpleasant and strange, almost like distorted mechanical noise. I tested multiple audio files that I prepared myself and repeated steps 1 to 7, all resulting in the same issue.
These are my steps and the problem I'm facing (step 8). I expected that using the NAL-NL2 strategy would produce good amplification results since many hearing aids on the market still frequently use NAL-NL2 as a fitting rule. I don't know how to solve the issue I'm encountering, and I would greatly appreciate any ideas. Thank you.
If I play back the unprocessed sound followed by the processed sound at your chosen levels with the proposed method above(-5,+45,analogue amplifier), then the processed sound sounds annoyingly loud and annoyingly shrill, yes. The few clipped samples from your +50dB would make the processed sound more annoying, but in this case not by much because there are only so few clipped samples here.
However, I do have that hearing loss that the audiogram you gave describes, and you probably do not suffer from it either. Only people who actually have that hearing loss are the ones who should rate the quality of the processed sound, not you or me. Of course it sounds bad to us. The processing amplifies high frequencies for people who have 80dB HL thresholds at those high frequencies, therefore it must sound bad to us.